Using Copilot with Local Models via Ollama
Recently, Mistral AI released a highly efficient code-writing model called codestral. It’s only 22B, and my MacBook can easily handle it, using around 15GB of memory during operation. I wanted to integrate it with VSCode to replace GitHub Copilot for more secure coding.
Ensure you have Ollama and the codestral model installed. It’s straightforward following the official links.
To use a Copilot-like feature in VSCode, you need to install codestral and starcoder2 via Ollama, then install the Continue plugin in VSCode. Ensure Ollama is running by checking localhost:11434.
In the Continue plugin, select the local model. Remember to install starcoder2—it’s essential for TAB completion features!
Using Copilot with Privately Hosted Models via Ollama
Not everyone can run a 22B model locally or on mobile devices. If you have a capable host device, you can deploy Ollama on it and access it remotely.
To allow access, set Ollama to run on 0.0.0.0, so other devices can connect. Refer to:
Setting environment variables on Linux
Setting environment variables on Linux
If Ollama is run as a systemd service, environment variables should be set using
systemctl:
Edit the systemd service by calling
systemctl edit Ollama.service. This will open an editor.For each environment variable, add a line
Environmentunder section[Service]:[Service] Environment="OLLAMA_HOST=0.0.0.0"Save and exit.
Reload
systemdand restart Ollama:systemctl daemon-reload systemctl restart ollama
[!WARNING]
Be aware! If Ollama updates, it might alter your service file, requiring you to re-edit and save it!
I deployed this on my Debian-based ITX device. After ensuring Ollama, codestral, and starcoder2 are installed, modify the Ollama.service configuration file and restart. Verify access on your local machine via ip:11434.
If you use iptables or ufw, remember to open port 11434 for access.
Then, edit the Continue extension configuration in VSCode. My config file is at /Users/bdim404/.continue/config.json. You can also modify it via Continue’s settings icon, using your remote Ollama configuration. Key parameter is "apiBase".
Example configuration:
{
"models": [
{
"model": "AUTODETECT",
"title": "Ollama in itx",
"apiBase": "http://192.168.51.154:11434",
"provider": "Ollama"
}
],
"customCommands": [
{
"name": "test",
"prompt": "{{{ input }}}\n\nWrite a comprehensive set of unit tests for the selected code. It should setup, run tests that check for correctness including important edge cases, and teardown. Ensure that the tests are complete and sophisticated. Give the tests just as chat output, don't edit any file.",
"description": "Write unit tests for highlighted code"
}
],
"tabAutocompleteModel": {
"title": "Starcoder 3b",
"provider": "Ollama",
"apiBase": "http://192.168.51.154:11434",
"model": "starcoder2"
},
"allowAnonymousTelemetry": true,
"embeddingsProvider": {
"provider": "transformers.js"
}
}
Save the configuration and select the Ollama in ITX model in Continue for testing.
Model Recommendations
For Code Writing Copilot Chat:
- codestral 22B (requires around 15GB of memory; insufficient memory may slow down or freeze generation).
- codeqwen 7B.
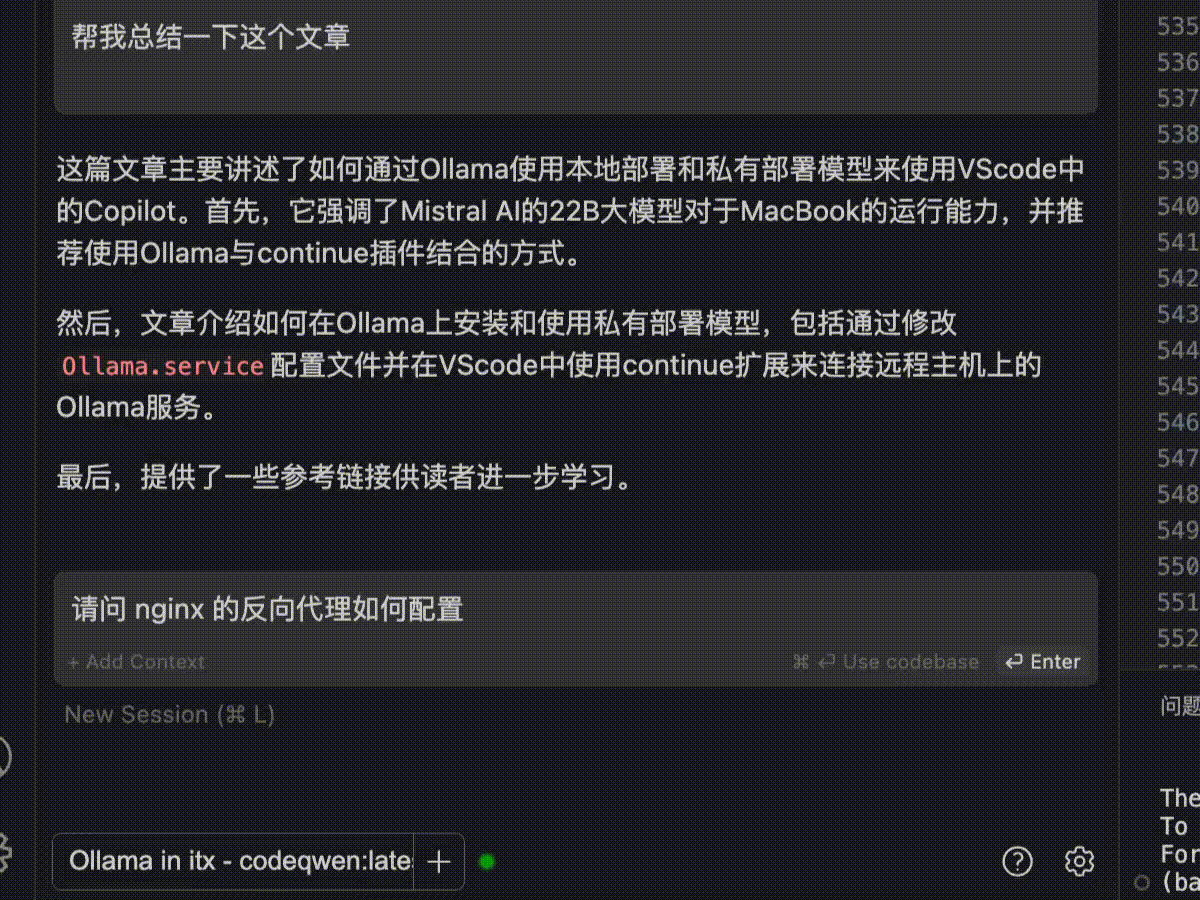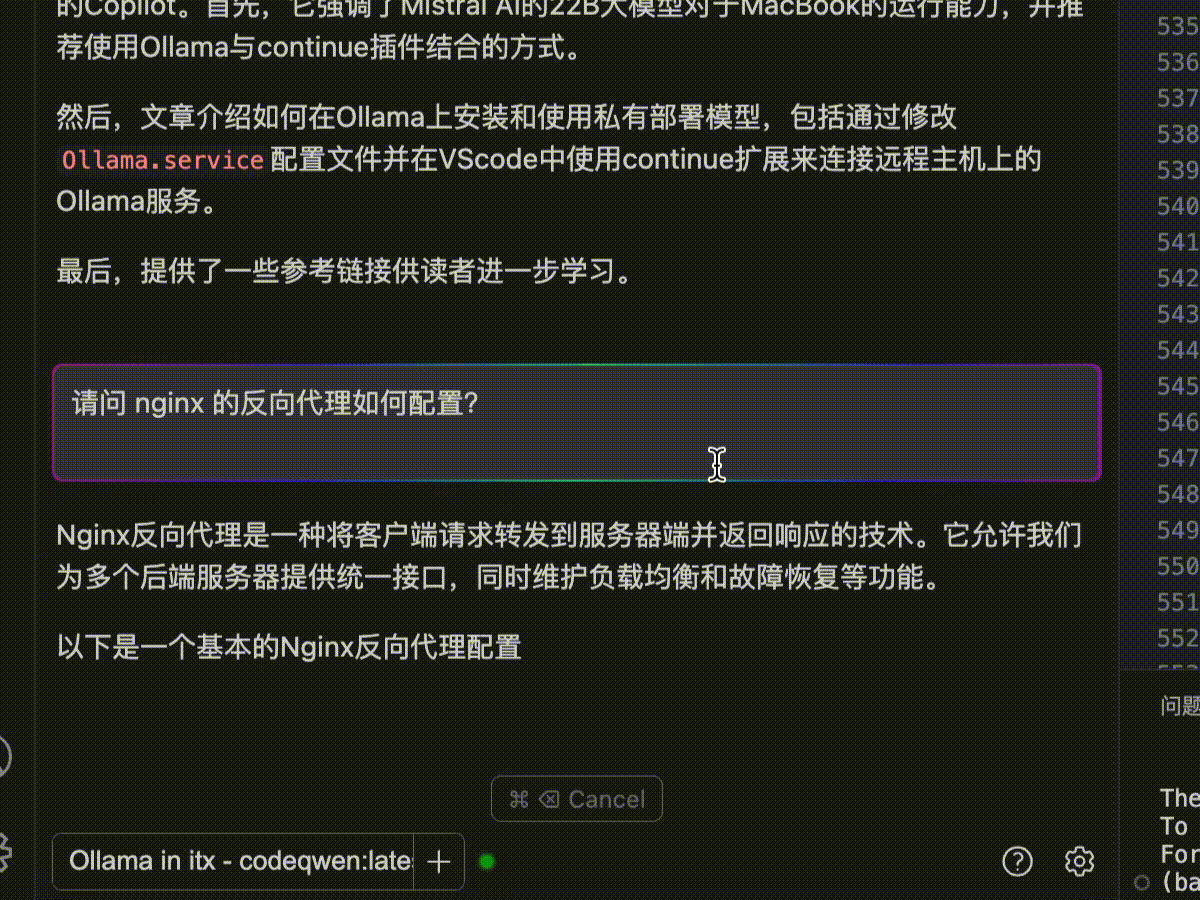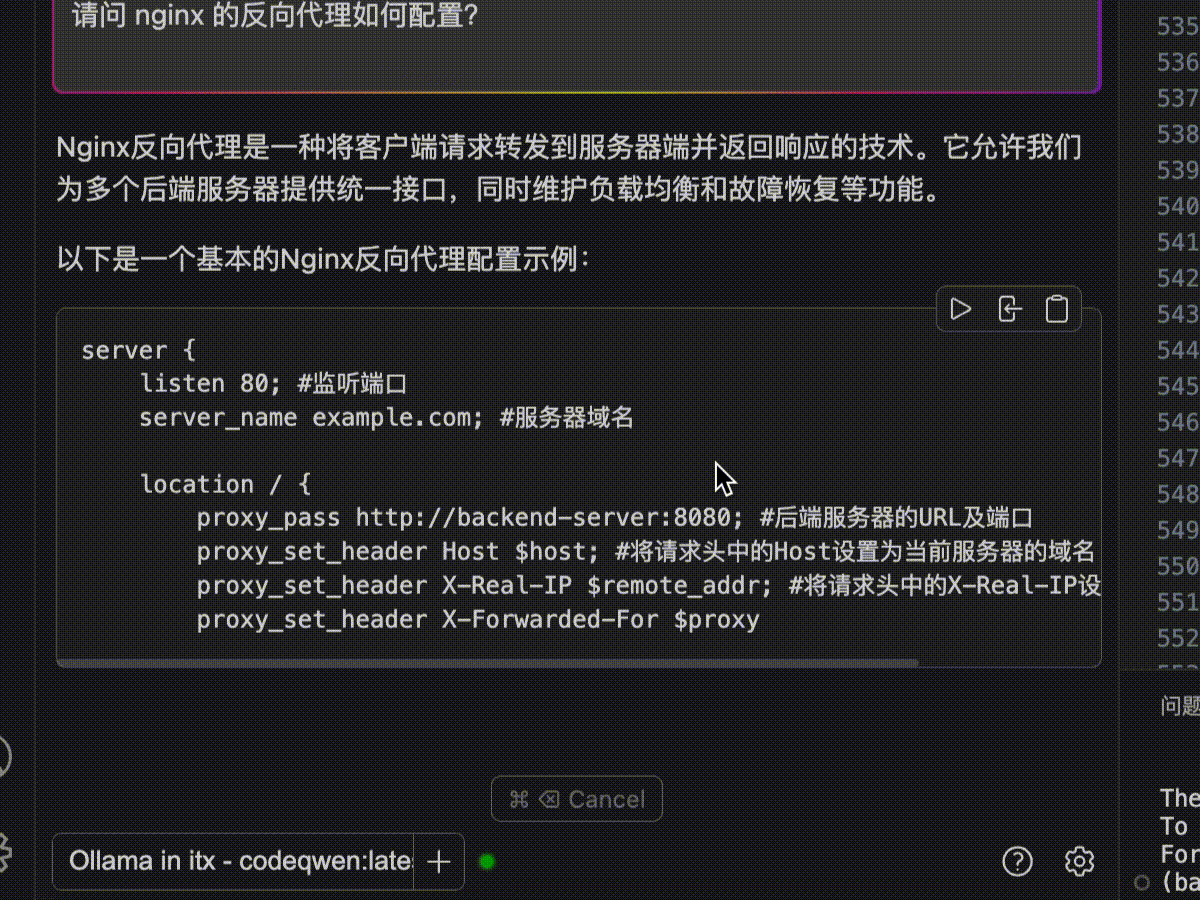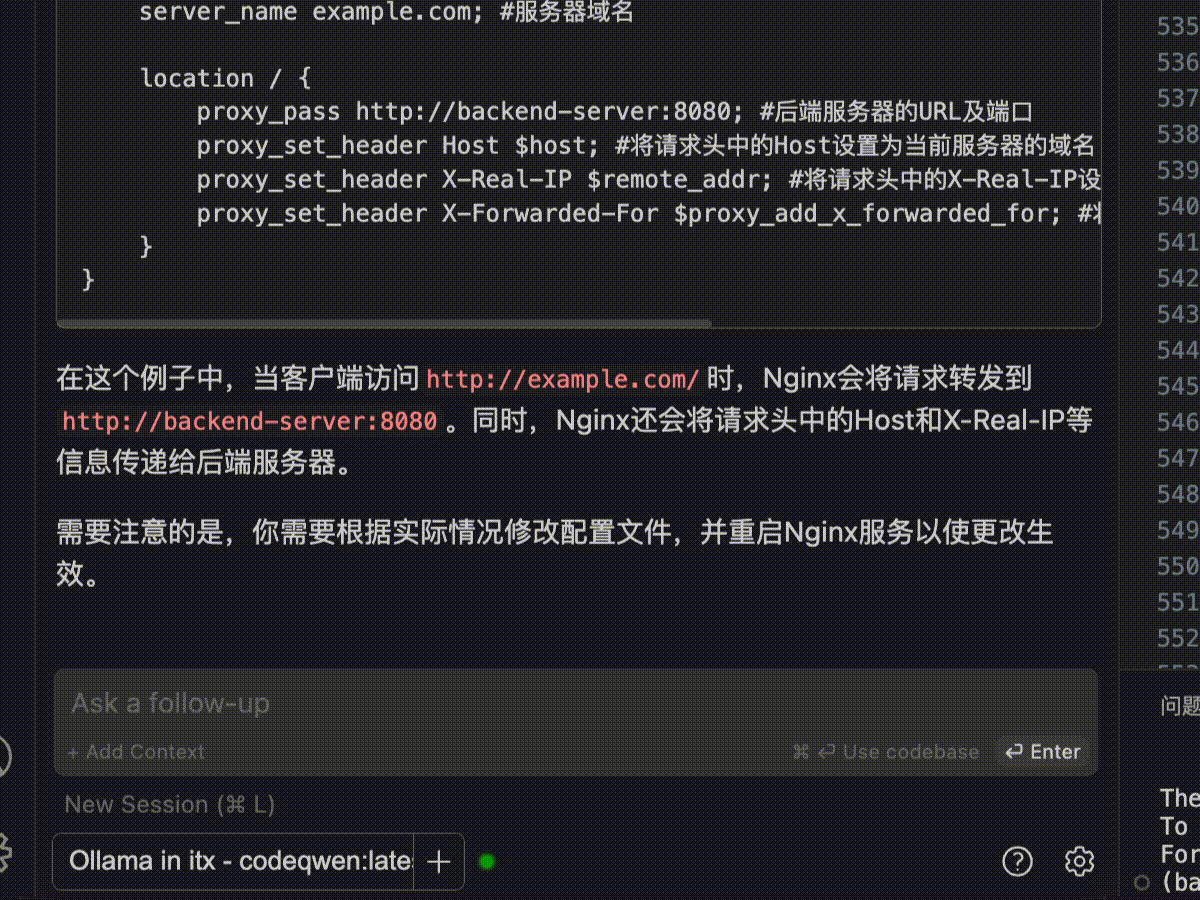
Both models are optimized for coding.
For TAB Autocomplete:
- starcoder2 3B.