Core Ideas
1. Background of the Study:
- This paper explores how to implement an end-to-end Optical Music Recognition (OMR) system using deep learning methods, with a focus on recognizing pianoform music. While recent progress has been made in monophonic music recognition, existing OMR models struggle to handle the multi-voice and multi-staff nature of piano music.
- The complexity of piano music stems from its independent parallel voices, which can freely appear and disappear within a composition. This complexity introduces additional challenges for the output of OMR models.
2. Key Contributions:
-
Linearized MusicXML Encoding: The paper proposes a linearized MusicXML format (Linearized MusicXML) that allows end-to-end models to be directly trained while maintaining close compatibility with the industry-standard MusicXML format.
- This encoding method involves a depth-first traversal of the XML tree, converting each element into a corresponding token. This reduces redundancy, focuses on the visual representation of the score, suppresses semantic information, and ignores sound, layout, and metadata.
-
Dataset Construction and Testing: A benchmark dataset for piano music was constructed based on the OpenScore Lieder corpus, containing synthetic training images and real-world images from public IMSLP scans.
- The dataset includes two variants: synthetic and scanned, used respectively for training, development, and testing. Synthetic data is used for initial model training, while scanned data is used to test the model’s real-world performance.
-
Model Training and Optimization: The model is trained using a new LSTM-based architecture, which is fine-tuned to serve as a benchmark.
- The model performs well on both synthetic and scanned test sets, significantly surpassing the state-of-the-art results on existing piano music datasets.
-
Evaluation Metrics and Results Analysis: The TEDn metric is used to evaluate the output MusicXML files, and the results are compared with the current state-of-the-art, demonstrating the effectiveness of the new encoding and model architecture for piano music OMR tasks.
- The results show that the end-to-end OMR system with LMX linearization achieves state-of-the-art performance in piano music recognition.
3. Technical Implementation:
-
Model Architecture: The paper proposes a new sequence-to-sequence architecture that combines an LSTM decoder with Bahdanou attention mechanism for optical recognition of piano music.
- The model first processes input images through several convolutional layers, then encodes the context using bidirectional LSTM layers, and finally generates the output using an LSTM decoder with an attention mechanism.
-
Data Augmentation and Training Strategy: To address the differences between synthetic and real scanned data, a series of data augmentation operations are designed, such as horizontal and vertical shifts, rotations, etc., to improve the model’s generalization ability.
- The model is trained using the Adam optimizer with a cosine decay learning rate strategy, enhancing robustness to different inputs.
Technical Details
1. Linearized MusicXML Encoding
Background and Motivation:
- Traditional MusicXML is a tree-structured format containing detailed musical representation information, such as notes, relationships between notes, key signatures, time signatures, etc. While MusicXML is widely used and supported by various music notation software, its verbose and complex structure is not suitable for directly training sequence-to-sequence deep learning models.
- To enable the model to directly generate standardized MusicXML files, the paper proposes the Linearized MusicXML (LMX) encoding method, which converts the tree structure of MusicXML into a linear sequence that can be used in sequence-to-sequence models for training and inference.
Encoding Process:
- Depth-First Traversal: By performing a depth-first traversal of the XML tree, MusicXML elements are converted one by one into tokens. The order of elements is determined by the MusicXML specification, ensuring that the generated linear sequence is consistent with the original musical information.
- Simplification and Optimization:
-
To reduce redundancy and improve model efficiency, LMX encoding simplifies the representation of some elements. For example, for the
<type>element of a note, only its value (such as “quarter”, “16th”) is used without including the type identifier, as these values already convey sufficient information.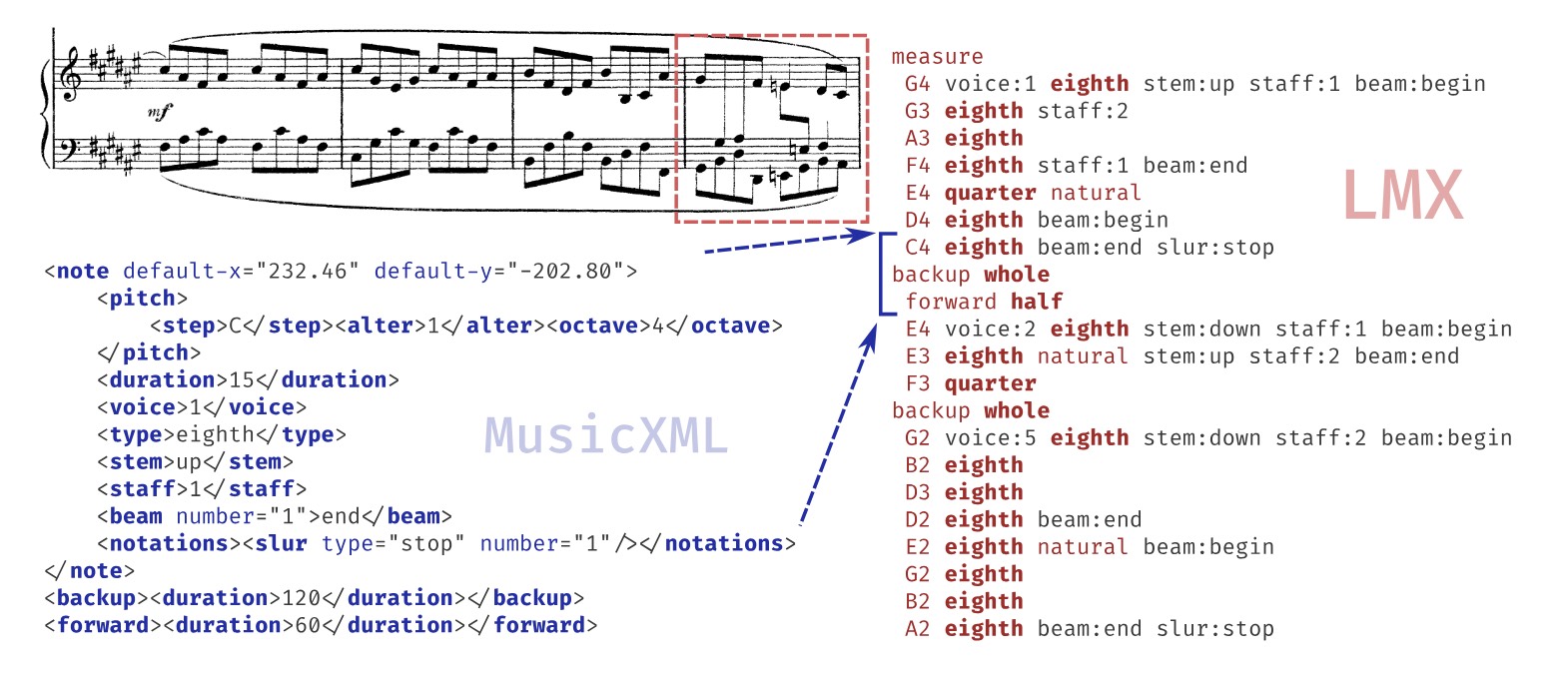
Practical End-to-End Optical Music Recognition for Pianoform Music (Source: https://arxiv.org/pdf/2403.13763)
-
For note properties (such as voice number, staff number, and stem direction), LMX uses state change encoding instead of absolute state encoding, meaning that relevant tokens are only re-emitted when a state change occurs.
-
Elements unrelated to the musical semantics, such as the
<duration>element and<tie>element (used for note ties), are ignored, and only visual elements are encoded to maintain consistency with MusicXML semantics.
-
Advantages of Encoding:
- Reduction of Redundancy: LMX encoding significantly reduces the redundancy of training data, making model training more efficient.
- Ease of Parsing and Reconstruction: LMX encoding is simple in design and retains sufficient musical information, allowing for accurate reconstruction to the original MusicXML structure during decoding.
2. OLiMPiC Dataset
Dataset Construction:
- The paper introduces two datasets: a synthetic dataset based on the OpenScore Lieder corpus and a real-world dataset constructed from actual scanned scores obtained from IMSLP. These two datasets are used for model training and evaluation, respectively.
Synthetic Dataset:
- GrandStaff-LMX: The GrandStaff dataset is converted into the MusicXML format and further transformed into the LMX format. This dataset contains approximately 53,882 data samples, covering various piano staff configurations and is used for model training on synthetic images.
- OLiMPiC Synthetic: The OpenScore Lieder corpus is processed using MuseScore software to generate standardized MusicXML files and their corresponding PNG and SVG images. The customized linearization procedure then produces LMX annotations for each sample. This synthetic dataset contains 17,945 samples, divided into training, development, and testing sets.
Real-World Dataset:
- OLiMPiC Scanned: This dataset is extracted from actual scores scanned from IMSLP and manually annotated, containing real-world score images. This dataset is used to evaluate the model’s performance in real-world scenarios.
Dataset Characteristics:
- Both the synthetic and scanned OLiMPiC datasets have identical training/development/testing splits, enabling fair evaluation of the model’s performance on different data sources.
- These datasets specifically focus on the complexity of pianoform music, including multiple voices, note relationships, and ornamentations, ensuring that the model can handle the complexity of piano music in real-world scenarios.
3. Model Architecture
Architecture of model. (Source: https://arxiv.org/pdf/2403.13763)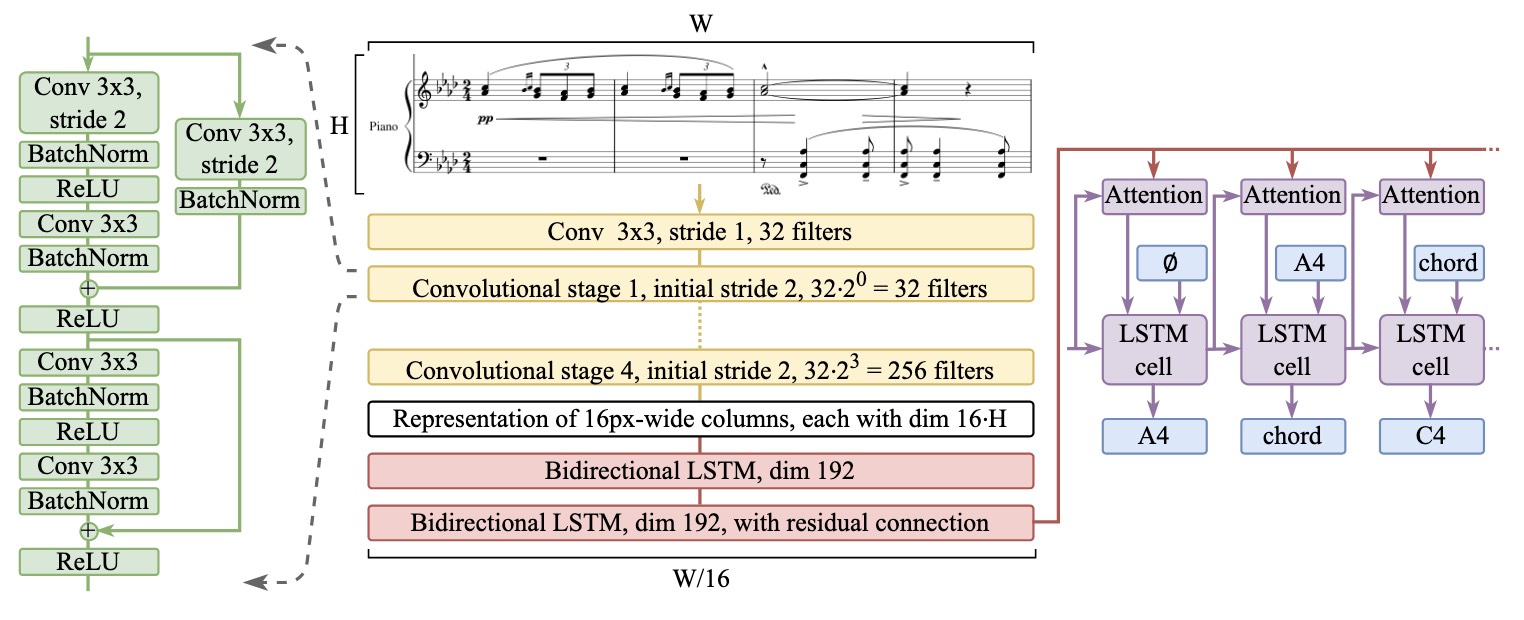
- Zeus Model: The Zeus model proposed in the paper is a sequence-to-sequence model based on LSTM and the Bahdanou attention mechanism. The model comprises three main components:
- Convolutional Encoder: The input score image first passes through a 3×3 convolution layer, followed by four convolutional blocks for feature extraction. Each convolutional block contains two ResNet-like residual blocks (with Batch Normalization and ReLU activation), with the first convolution in a stage having a stride of 2 to reduce the feature map size and progressively increase the number of filters.
- Bidirectional LSTM Encoder: The extracted image features are encoded contextually using two bidirectional LSTM layers, with the second LSTM layer employing a residual connection to enhance the model’s capture capabilities.
- Attention Decoder: An LSTM decoder with Bahdanou attention mechanism is used to convert the encoded features into an output sequence, generating the corresponding LMX encoding.
Model Optimization:
- Exclusion of Transformer: The paper deliberately avoids using the Transformer architecture, despite its excellent performance on some tasks. Transformers require large amounts of data for training and lack the locality bias of LSTMs. The authors argue that LSTMs are more suitable for this task given the current data scale.
- Data Augmentation: To enhance the model’s generalization ability to real-world data, the paper designs a series of data augmentation operations, including horizontal and vertical shifts, rotations, contrast, and brightness adjustments. These operations are applied to synthetic data to simulate scanned images from the real world and improve model robustness.
Training and Evaluation:
- Optimizer and Learning Rate: The model is trained using the Adam optimizer with a cosine decay learning rate strategy on a 40GB A100 GPU for 500 epochs with a batch size of 64.
- Evaluation Metrics: The TEDn metric is used as the primary evaluation metric, comparing the output MusicXML files from the model with the actual MusicXML files. Additionally, traditional metrics like Symbol Error Rate (SER) and Line Error Rate (LER) are used for model comparison.
4. Experiments and Results
Results on GrandStaff-LMX Dataset:
- Performance: The Zeus model reduces error rates by 50% compared to other models on the GrandStaff and Camera GrandStaff datasets, achieving the best results across various evaluation metrics.
Results on OLiMPiC Dataset:
- Synthetic Dataset: On the synthetic OLiMPiC dataset, the Zeus model achieves
an SER of 11.3% and a TEDn score of 13.7%.
- Scanned Dataset: On the real-world scanned dataset, the model without data augmentation performs poorly, while the model with data augmentation significantly improves, achieving a TEDn score of 18.4%, demonstrating its potential for real-world application.
Conclusion
I find the ideas in this paper to be very innovative, aligning closely with my previous thoughts. MusicXML is a highly comprehensive digital sheet music recording format that effectively captures score information. By applying linearization, much of the “noise” can be eliminated, making it easier for models to learn key content during deep learning. Meanwhile, less critical content, especially those that can be reconstructed based on rules, can be handled through additional tools.