核心观点
1. 研究背景 (Background of the Study):
- 文章探讨了如何通过深度学习方法实现光学音乐识别 (OMR) 的端到端系统,尤其是针对钢琴形式音乐的识别。尽管近年来在单声部音乐的光学识别方面取得了进展,但现有的 OMR 模型很难处理钢琴音乐中包含的多声部和多行谱表。
- 钢琴音乐的复杂性源于其多声部的独立并行,声部可以在乐曲中自由出现和消失。这种复杂性给 OMR 模型的输出带来了额外的挑战。
2. 核心贡献 (Key Contributions):
-
Linearized MusicXML 编码: 提出了一个线性化的 MusicXML 格式 (Linearized MusicXML),以便端到端模型直接训练,同时保持与行业标准 MusicXML 格式的紧密一致性。
- 这种编码方法通过对 XML 树进行深度优先遍历,并将每个元素转换为相应的令牌,从而减少冗余,专注于乐谱的视觉表示,抑制语义信息并忽略声音、布局和元数据。
-
数据集构建与测试: 构建了一个基于 OpenScore Lieder 语料库的钢琴音乐基准测试集,包含合成训练图像和来自公共 IMSLP 扫描的真实世界图像。
- 数据集包括两种变体:合成和扫描,分别用于训练、开发和测试。合成数据用于模型的初始训练,扫描数据用于测试模型的真实性能。
-
模型训练与优化: 使用新的基于 LSTM 的模型架构进行训练,并进行了精调以作为基准。
- 模型在合成和扫描的测试集上都表现出色,显著超越了现有的钢琴音乐数据集上的最先进结果。
-
评价指标与结果分析: 采用 TEDn 度量模型来评估输出的 MusicXML 文件,并与当前最先进的结果进行比较,证明了新的编码和模型架构在钢琴音乐 OMR 任务中的有效性。
- 结果表明,使用 LMX 线性化的端到端 OMR 系统在钢琴音乐识别中达到了最先进的性能。
3. 技术实现 (Technical Implementation):
-
模型架构: 文章提出了一种新的 LSTM 解码器与 Bahdanou 注意力机制相结合的序列到序列架构,用于钢琴音乐的光学识别。
- 该模型首先通过多个卷积层处理输入图像,然后通过双向 LSTM 层进行上下文化,最后使用带有注意力机制的 LSTM 解码器生成输出。
-
数据增强与训练策略: 针对合成数据与真实扫描数据的差异,设计了一系列数据增强操作,如水平位移、旋转、垂直位移等,以提高模型的泛化能力。
- 模型在训练时使用了 Adam 优化器和余弦衰减的学习率策略,增强了模型对不同输入的鲁棒性。
技术细节
1. Linearized MusicXML 编码
背景与动机:
- 传统的 MusicXML 是一种树结构的格式,包含大量详细的音乐表示信息,如音符、音符之间的关系、调号、拍号等。虽然 MusicXML 被广泛使用并被多个乐谱编辑软件支持,但其冗长且复杂的结构并不适合直接用于训练序列到序列的深度学习模型。
- 为了让模型能够直接生成标准化的 MusicXML 文件,文章提出了 Linearized MusicXML (LMX) 编码方法,这种方法将 MusicXML 的树结构转换为线性序列,从而可以应用在序列到序列的模型中进行训练和推理。
编码过程:
- 深度优先遍历: 通过对 XML 树的深度优先遍历,将 MusicXML 元素逐一转换为令牌。元素的顺序由 MusicXML 规范决定,这确保了线性序列的生成与原始音乐信息一致。
- 简化与优化:
- 为减少冗余和提高模型效率,LMX 编码简化了一些元素的表示。例如,对于音符的
<type>元素,仅使用其值(如“quarter”、“16th”)而不包括类型标识符,因为这些值已经明确传达了足够的信息。
- 为减少冗余和提高模型效率,LMX 编码简化了一些元素的表示。例如,对于音符的
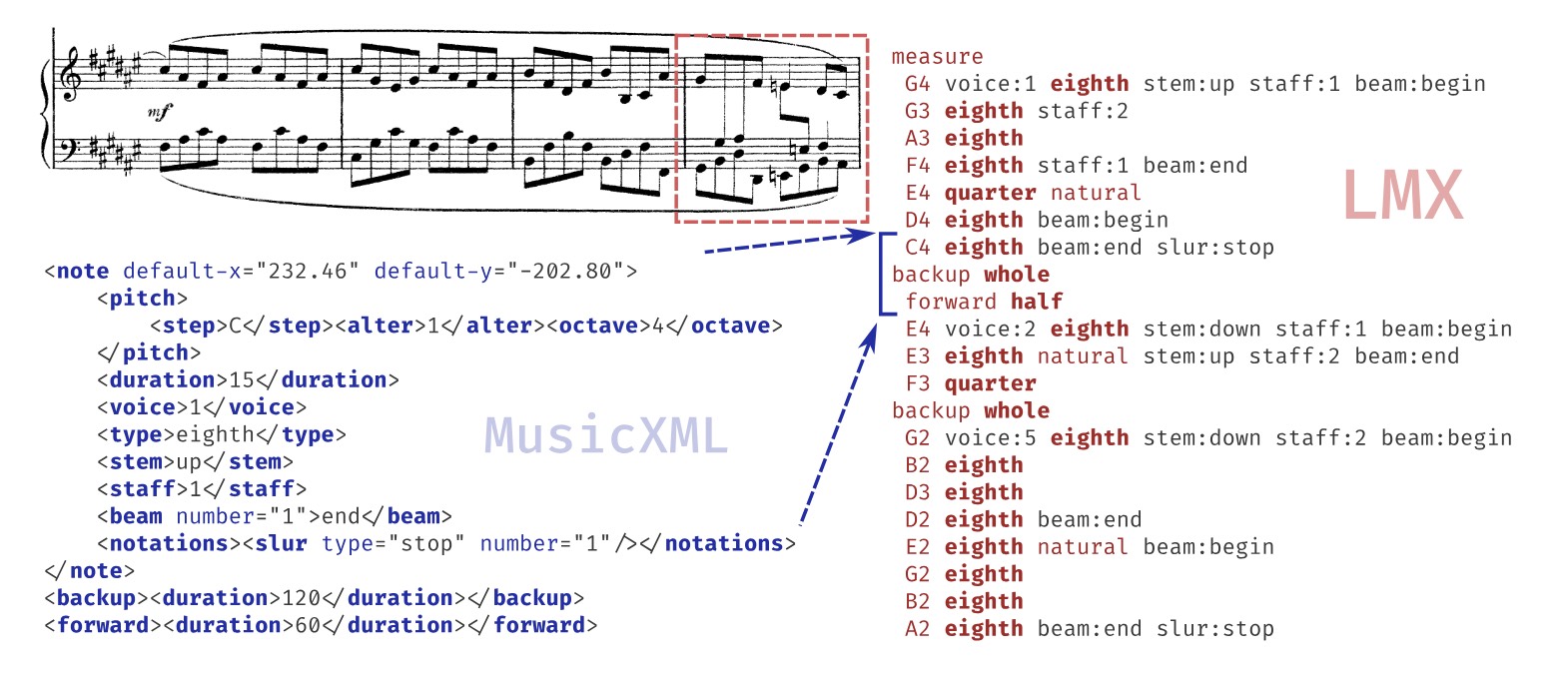
一个衡量标准 - 246 行 MusicXML 仅由 96 个 Linearized MusicXML 符号表示(格式化和缩进只是为了提高可读性)。 (Source: https://arxiv.org/pdf/2403.13763)
- 对于音符属性(如声部编号、谱表编号和音干方向),LMX 采用状态变化编码而非绝对状态编码,即只在状态变化时才重新发出相关令牌。
- 忽略与音乐语义无关的元素,如
<duration>元素和<tie>元素(用于音符连接),只编码视觉元素以保持与 MusicXML 语义的一致性。
编码优势:
- 减少冗余: LMX 编码显著减少了训练数据的冗余量,使模型训练更为高效。
- 易于解析与重建: LMX 编码设计简洁,并保留了足够的音乐信息,能够在解码过程中准确还原为原始的 MusicXML 结构。
2. OLiMPiC 数据集
数据集构建:
- 文章中提出了两个数据集:一个是基于 OpenScore Lieder 语料库构建的合成数据集,另一个是从 IMSLP 获取的实际扫描乐谱构建的真实数据集。这两个数据集分别用于模型训练和评估。
合成数据集:
- GrandStaff-LMX: 使用 GrandStaff 数据集,将其转换为 MusicXML 格式,并进一步转换为 LMX 格式。该数据集包含约53,882个数据样本,覆盖多种钢琴谱表配置,并在合成图像上进行模型训练。
- OLiMPiC Synthetic: 使用 MuseScore 软件对 OpenScore Lieder 语料库进行处理,生成标准化的 MusicXML 文件及其对应的 PNG 和 SVG 图像。之后通过自定义的线性化程序生成 LMX 注释文件。该合成数据集包含17,945个样本,且划分为训练、开发和测试集。
真实世界数据集:
- OLiMPiC Scanned: 该数据集从 IMSLP 扫描的实际乐谱中提取,经过手动注释,包含真实世界中的乐谱图像。这个数据集用于评估模型在真实环境中的表现。
数据集特点:
- 合成与扫描的 OLiMPiC 数据集有着相同的训练/开发/测试划分,从而可以公平地评估模型在不同数据源上的性能。
- 这些数据集特别注重钢琴形式音乐的复杂性,包括多声部、音符之间的关系、装饰音符等,确保模型能够处理真实世界中钢琴音乐的复杂情况。
3. 模型架构
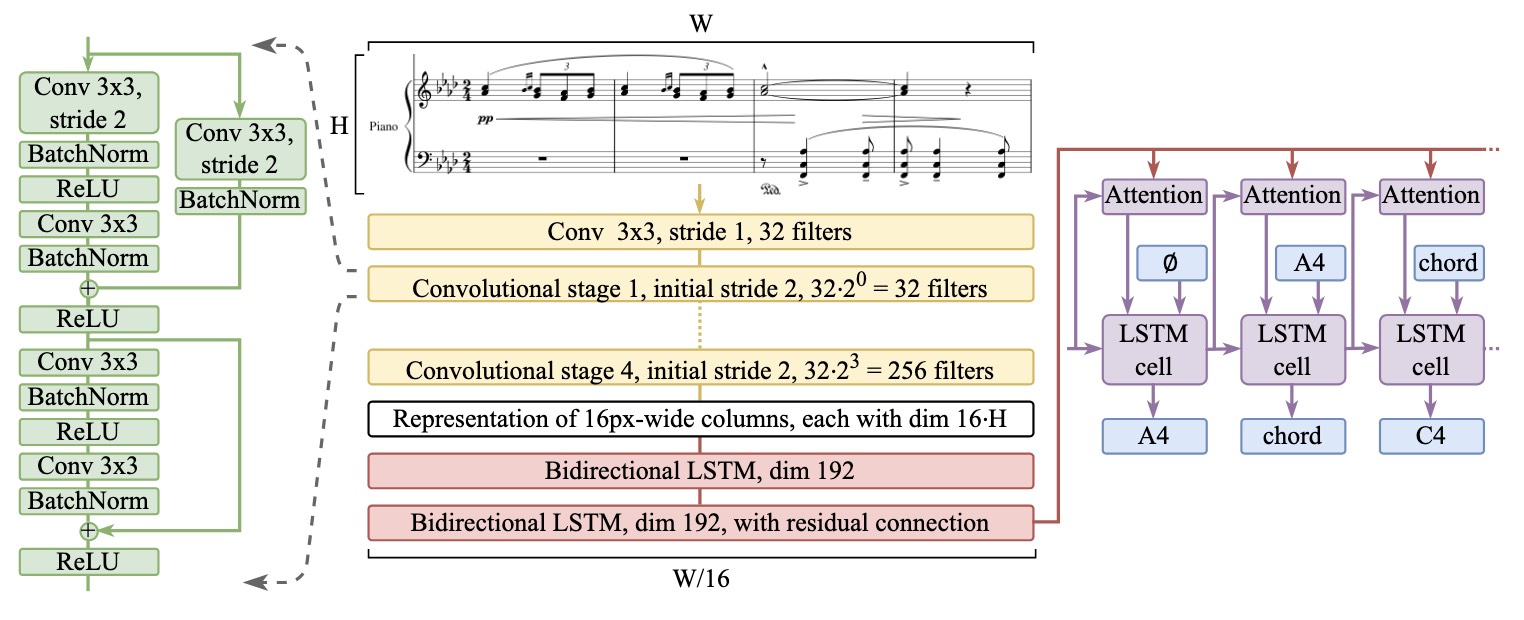
模型结构 (Source: https://arxiv.org/pdf/2403.13763)
模型设计:
- Zeus 模型: 文章提出的 Zeus 模型是一种基于 LSTM 和 Bahdanou 注意力机制的序列到序列模型。该模型由两个主要部分组成:
- 卷积编码器: 输入的乐谱图像首先经过一个3×3的卷积层,然后通过四个卷积块进行特征提取。每个卷积块包含两个 ResNet 风格的残差块(带有 Batch Normalization 和 ReLU 激活),第一层卷积采用步幅为2的卷积,以减少特征图的尺寸,并逐步增加过滤器的数量。
- 双向 LSTM 编码器: 提取的图像特征经过两个双向 LSTM 层进行上下文编码,第二个 LSTM 层使用残差连接以增强模型的捕捉能力。
- 注意力解码器: 使用 Bahdanou 注意力机制的 LSTM 解码器将编码后的特征转换为输出序列,生成对应的 LMX 编码。
模型优化:
- 不使用 Transformer: 文章特意选择不使用 Transformer 架构,尽管 Transformer 能够在某些任务上表现优异,但它需要大量的数据来训练,且不具备 LSTM 的局部性偏置特性。作者认为,在当前的数据规模下,LSTM 更适合此任务。
- 数据增强: 为了提高模型对真实世界数据的泛化能力,文章设计了一系列数据增强操作,包括水平和垂直位移、旋转、对比度和亮度调整等。这些操作在合成数据上进行,以模拟真实世界中的扫描图像,并提高模型的鲁棒性。
训练与评估:
- 优化器与学习率: 使用 Adam 优化器和余弦衰减的学习率策略进行训练,模型在40GB的 A100 GPU 上进行500个周期的训练,批量大小为64。
- 评估指标: 使用 TEDn 作为主要评估指标,该指标通过比较模型输出的 MusicXML 文件与实际的 MusicXML 文件进行评估。此外,还使用了传统的符号错误率 (SER) 和行错误率 (LER) 进行模型比较。
4. 实验与结果
GrandStaff-LMX 数据集结果:
- 性能表现: Zeus 模型在 GrandStaff 和 Camera GrandStaff 数据集上的错误率相较于其他模型降低了50%,在各项评估指标上都取得了最好的结果。
OLiMPiC 数据集结果:
- 合成数据集: 在合成的 OLiMPiC 数据集上,Zeus 模型取得了11.3%的 SER 和13.7%的 TEDn 指标。
- 扫描数据集: 在真实扫描数据集上,未进行数据增强的模型表现较差,而使用数据增强的模型则显著提高,TEDn 指标为18.4%,展现了模型在真实环境中的应用潜力。
总结
我认为这个文章对于编码的想法是非常先进的,和我之前的想法不谋而合。MusicXML 是一个非常全面的数字乐谱记录格式,能够很好的记录乐谱的信息,透过线性化的处理,能够摒弃很多 噪音 ,也更容易在深度学习过程中让模型学到关键的内容。而不重要的内容,尤其是能够根据规律还原的内容则透过额外的工具来进行处理。